Patching is an important task in every DBA life (and we patch quite often in the Oracle world :)) and the task is fairly easy (if well prepared). What is more tricky though is how to mitigate the downtime and the risks specially when you have no standby. Indeed, you do not want to have hours of downtime to apply a patch / PSU / RU nor not being able to easily rollback your patch / PSU / RU in case of something goes wrong. Also, you do not want to work all your WE long applying patches then the more you can do during weekdays the better.
Hopefully, this is the purpose of the "out of place rolling patching" method with you can achieve a very very close to 0 downtime (as well as 0 risk) patch application. Let's see how it works.
Hopefully, this is the purpose of the "out of place rolling patching" method with you can achieve a very very close to 0 downtime (as well as 0 risk) patch application. Let's see how it works.
0/ Introduction
Few points to keep in mind to enjoy this blog as best as possible:
- The source database home: /u01/app/oracle/product/12.2.0.1/dbhome_1
- The target database home: /u01/app/oracle/product/12.2.0.1/dbhome_2
- The example below will be executed on a 2 nodes RAC (please have a look at the end of this blog if you have no RAC); it is exactly the same with more nodes
- This method works for any patch application whether you apply a one-off patch, a PSU/RU and whatever your database version is
- I may name the database ORACLE_HOME as "OH"
- The below example has been executed on Exadatas but it works the same exact way on non-Exadata systems
1/ Out of place
The first words in "out of place rolling" is "out of place" which means that we won't patch the source OH (dbhome_1) but another cloned OH (dbhome_2).
1.1/ OH Clone
First of all, we will be cloning the current OH to a new one.
$ cp -r /u01/app/oracle/product/12.2.0.1/dbhome_1 /u01/app/oracle/product/12.2.0.1/dbhome_2 $ cd /u01/app/oracle/product/12.2.0.1/dbhome_2/oui/bin $ ./runInstaller -clone -waitForCompletion ORACLE_HOME="/u01/app/oracle/product/12.2.0.1/dbhome_2" ORACLE_HOME_NAME="JULY2019" ORACLE_BASE="/u01/app/oracle" CLUSTER_NODES="{exadatadb01,exadatadb02}" LOCAL_NODE="exadatadb01" -silentYou now get a new cloned OH (dbhome_2) which is the same exact as your current one (dbhome_1).
1.2/ Patch application against dbhome_2
We will now apply the patch(es) we want against our target OH dbhome_2 (below an example with the July 2019 RU but it can be any patch):
# Upgrade opatch . . . # Patches pre-requisites . . . # Apply OJVM $ cd /patches/29698987/Database/12.2.0.1.0/12.2.0.1.190716OJVMRU/29774415 $ $ORACLE_HOME/OPatch/opatch apply # Apply PSU (as root) # /u01/app/oracle/product/12.2.0.1/dbhome_2/OPatch/opatchauto apply /patches/29698987/Database/12.2.0.1.0/12.2.0.1.190716GIRU/29708720 -oh /u01/app/oracle/product/12.2.0.1/dbhome_2Here your dbhome_2 OH is ready and fully patched and all this has been done with no disruption of the production database running on the same server and you did all this work during your weekdays -- cool, right ?
1.3/ Clone dbhome_2 on the other nodes
Now that we have our dbhome_2 ready, it is time to clone it on the other nodes:
All right, we are not ready to patch our production database !
$ cd /u01/app/oracle/product/12.2.0.1 $ tar czf dbhome_2.tgz dbhome_2 $ scp dbhome_2.tgz oracle@exadatadb02:/u01/app/oracle/product/12.2.0.1/. $ ssh exadatadb02 $ cd /u01/app/oracle/product/12.2.0.1 $ tar xf dbhome_2.tgz $ cd dbhome_2/oui/bin $ ./runInstaller -clone -waitForCompletion ORACLE_HOME="/u01/app/oracle/product/12.2.0.1/dbhome_2" ORACLE_HOME_NAME="JULY2019" ORACLE_BASE="/u01/app/oracle" CLUSTER_NODES="{exadatadb01,exadatadb02}" LOCAL_NODE="exadatadb02" -silent
2/ Rolling
Now that we have prepared the "out of place" by pre-patching a dbhome_2 target OH, we will do the "rolling" part meaning that we will restart (patch) the database from the source OH dbhome_1 to the target OH dbhome_2 instance by instance.
2.1/ Starting position
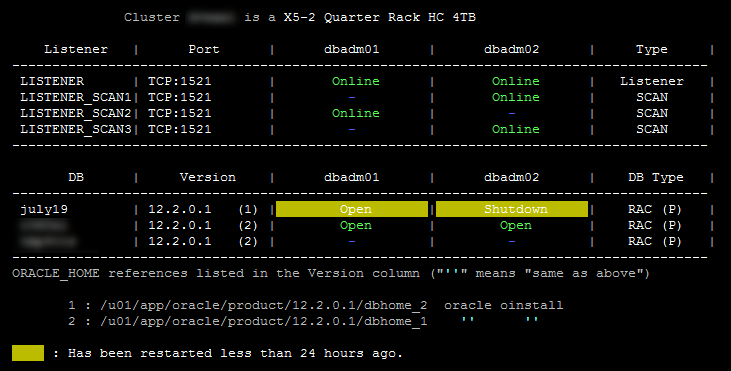
To illustrate this, I will use outputs from the rac-status.sh script to make it clear and visible. Here is the starting point with a JULY19 database I have created using dbca (this procedure has also been successfully applied on "real" databases full of data but as every name is confidential, I show the procedure with a database I have created myself):

We can see here a 2 nodes RAC with databases running on the dbhome_1 OH, the JULY19 database is the one we will migrate to our already patched target OH dbhome_2. Note that here dbhome_2 is not shown by rac-status.sh; this is because the OH are not registered in the cluster. It may be the case in the future as discussed in this blog but so far they are not.
We can see here a 2 nodes RAC with databases running on the dbhome_1 OH, the JULY19 database is the one we will migrate to our already patched target OH dbhome_2. Note that here dbhome_2 is not shown by rac-status.sh; this is because the OH are not registered in the cluster. It may be the case in the future as discussed in this blog but so far they are not.
2.2/ Update database configuration
As the goal here is to restart the JULY19 instances on dbhome_2, we first need to update the database configuration which resides in the cluster:
$ srvctl config database -d july19 # ORACLE_HOME should point to dbhome_1 $ srvctl modify database -db july19 -oraclehome /u01/app/oracle/product/12.2.0.1/dbhome_2 $ srvctl config database -d july19 # ORACLE_HOME should now point to dbhome_2
2.3/ Shutdown instance on node 1
Let's now shutdown the instance 1 from dbhome_1:
 We can see here that the instance 1 is well shutted down and the instance 2 has a very interesting status "Open,Running from Old Oracle Home". Also, rac-status.sh now shows that JULY19 is running on dbhome_2; indeed, we have updated the cluster configuration so JULY19 is now supposed to run on dbhome_2 ! The instance 2 is still opened for connection and no one connected to the instance 2 has been disconnected.
We can see here that the instance 1 is well shutted down and the instance 2 has a very interesting status "Open,Running from Old Oracle Home". Also, rac-status.sh now shows that JULY19 is running on dbhome_2; indeed, we have updated the cluster configuration so JULY19 is now supposed to run on dbhome_2 ! The instance 2 is still opened for connection and no one connected to the instance 2 has been disconnected.
$ srvctl stop instance -d july19 -i july191Which leads to the below status:
2.4/ Restart instance on node 1
We can then restart the instance 1:
 As expected, both instances are now opened, instance 1 running on dbhome_2 and the instance 2 still on the old dbhome_1.
As expected, both instances are now opened, instance 1 running on dbhome_2 and the instance 2 still on the old dbhome_1.
$ srvctl start instance -d july19 -i july191And have a look at how it looks:
2.5/ Restart instance 2 on dbhome_2
You guess the coming actions now, let's stop the instance 2 from dbhome_1:
And restart it on dbhome_2:
The "out of place rolling" has been succesfully executed !
$ srvctl stop instance -d july19 -i july192To get the below status:
And restart it on dbhome_2:
$ srvctl start instance -d july19 -i july192To be in the final status:
3/ Datapatch
3.1/ update oraenv
Now that our instances are running on dbhome_2, it is a good time to update oratab (on all nodes) not to mess up with the old environment:
$ dcli -g ~/dbs_group -l oracle grep -i july /etc/oratab exadatadb01: july191:/u01/app/oracle/product/12.2.0.1/dbhome_2:N exadatadb02: july192:/u01/app/oracle/product/12.2.0.1/dbhome_2:N $
3.2/ Datapatch
If you look at dba_registry_sqlpatch, you will see that despite the fact that your instances are restarted on the fully patched home dbhome_2, the patches are NOT applied against the database (below are still the July 18 patches and not July 19 patches we want to apply):
SQL> @check_patches ACTION_TIME ACTION STATUS DESCRIPTION VERSION PATCH_ID BUNDLE_SER -------------------- ---------- ---------- -------------------------------------------------------------------------------- ---------- ---------- ---------- 15-AUG-2019 03:30:44 APPLY SUCCESS OJVM RELEASE UPDATE: 12.2.0.1.170718 (25811364) 12.2.0.1 25811364 15-AUG-2019 03:30:45 APPLY SUCCESS DATABASE JUL 2018 RELEASE UPDATE 12.2.0.1.180717 12.2.0.1 28163133 DBRU SQL> get check_patches.sql 1 SET LINESIZE 400 2 SET PAGESIZE 100 3 COLUMN action_time FORMAT A20 4 COLUMN action FORMAT A10 5 COLUMN status FORMAT A10 6 COLUMN description FORMAT A80 7 COLUMN version FORMAT A10 8 COLUMN bundle_series FORMAT A10 9 SELECT TO_CHAR(action_time, 'DD-MON-YYYY HH24:MI:SS') AS action_time, 10 action, 11 status, 12 description, 13 version, 14 patch_id, 15 bundle_series 16 FROM sys.dba_registry_sqlpatch 17* ORDER by action_time; 18 /This is expected and it is datapatch's job to apply these SQL patches:
$ . oraenv <<< july191 $ echo $ORACLE_HOME # This has to be /u01/app/oracle/product/12.2.0.1/dbhome_2 $ cd $ORACLE_HOME/OPatch $ ./datapatch -verbose . . .Once datapatch has been successfully executed, you will see the correct July 19 patches properly installed:
SQL> @check_patches ACTION_TIME ACTION STATUS DESCRIPTION VERSION PATCH_ID BUNDLE_SER -------------------- ---------- ---------- -------------------------------------------------------------------------------- ---------- ---------- ---------- 26-AUG-2019 21:40:26 APPLY SUCCESS OJVM RELEASE UPDATE: 12.2.0.1.170718 (25811364) 12.2.0.1 25811364 26-AUG-2019 21:40:27 APPLY SUCCESS DATABASE JUL 2018 RELEASE UPDATE 12.2.0.1.180717 12.2.0.1 28163133 DBRU 26-AUG-2019 22:04:46 APPLY SUCCESS OJVM RELEASE UPDATE: 12.2.0.1.190716 (29774415) 12.2.0.1 29774415 26-AUG-2019 22:04:46 APPLY SUCCESS DATABASE JUL 2019 RELEASE UPDATE 12.2.0.1.190716 12.2.0.1 29757449 DBRU 26-AUG-2019 22:04:46 ROLLBACK SUCCESS OJVM RELEASE UPDATE: 12.2.0.1.170718 (25811364) 12.2.0.1 25811364 SQL>
4/ Sum up / downtime and risk mitigation
To sum that up and to be exhaustive:
If you have no RAC, you can still use the same method, the only thing is that you won't avoid a downtime but you can mitigate it seriously as the only downtime you will suffer is when you will stop / restart the instance to dbhome_2 which is what ... 1 minute ?
And as we are in a renewable world, I would suggest you to reuse dbhome_1 next time you out place rolling patch ! (from dbhome_2 to dbhome_1)
A last thing: since 12.2 you can also do this using opatchauto. As I am a bit cautious with the new features and knowing that all of this is easy, I still prefer doing it that way !
- We have mitigated the risk to I would say 0 by following an out of place patching. If something goes wrong, just restart your instances on dbhome_1 and if you need to fallback as the patch(es) you have applied cause more issues than resolve problems, you just have to restart on dbhome_1, execute datapatch from dbhome_1 and you are done !
- The downtime has been mitigated by the rolling method and we can even do better by using the services I haven't emphasys earlier to focus on the rolling instances method but a whole downtime mitigated patch would be:
- Stop services on node 1 / relocate to node 2
- Stop / restart instance 1 from dbhome_1 to dbhome_2
- Stop services on node 2 / relocate to node 1
- Stop / restart instance 2 from dbhome_1 to dbhome_2
- Datapatch
- Relocate the services as you like
- Relocating a service does not kill any session by default
- You can wait for any session to finish before restarting the instances, there is no time limit to stay in "Open,Running from Old Oracle Home" mode so take your time, the users will thank you !
If you have no RAC, you can still use the same method, the only thing is that you won't avoid a downtime but you can mitigate it seriously as the only downtime you will suffer is when you will stop / restart the instance to dbhome_2 which is what ... 1 minute ?
And as we are in a renewable world, I would suggest you to reuse dbhome_1 next time you out place rolling patch ! (from dbhome_2 to dbhome_1)
A last thing: since 12.2 you can also do this using opatchauto. As I am a bit cautious with the new features and knowing that all of this is easy, I still prefer doing it that way !
Enjoy the out of place rolling way of patching !



Fred, is possible to apply the same technique for patching the Grid?
ReplyDelete100% yes !
DeleteFred, thanks for your reply. I planning to upgrade a single instance (no RAC) Grid from 19.3.0 to 19.5.0. I have installed the 19.5.0 RU into another OH, using a golden image. I created a 19.5.0 golden image, using 19.3.0 base release and 19.5.0 RU patch using the technique described by Liron Amitzi in https://gotodba.com/2019/10/01/using-oracle-gold-images.
DeleteSo now I have a currently running grid in 19.3.0 OH Grid Home and a 'empty' but configured 19.5.0 OH Grid Home. No software is been run using this 19.5.0 OH Grid Home.
I would like to move/patch/update/upgrade my current Grid/CRS from 19.3.0 to 19.5.0.
I have performed a DB RU update successfully using this technique, in where I didn't perform a single opatch call...
Is it possible to do same to Grid without a opatchauto call?
If I'm not wrong
ReplyDeleteyou should:
-stop db
-modify the home
-start db (in some cases also only in upgrade mode)
and not as shown above (unless oracle uses the old running home)
upgrade mode is for upgrade, this blog shows how to rolling patch so there is no upgrade mode
Deletethe fact that I change the Home before is to save time and reduce the number of stop start when patching the DB OH is included in a bigger maintenance including GI patching / upgrade or OS patching / upgrade
Great post. We have a non-Grid, non-RAC 12.1.0.2 home under which we have several databases and have been looking to out of place patching. Will this work without the Grid infrastructure? ie can we clone the home, patch the new home, and apply the same methodology to patch the individual databases by shutting them down, starting them up under the new home and applying datapatch? If so, a couple of additional questions:
ReplyDelete1) can the cloning be done live (without shutting down the databases running under it)
2) in the event of a rollback, how do you roll back the datapatch? do we need to copy any scripts from the patched home to the original home before switching the database back to the original home and re-applying datapatch (again under the original home)?
Hi,
DeleteThanks !
Will this work without the Grid infrastructure? => Yes and Yes for your other question, you can do that
1) Yes you can do this online
2) just rerun the datapatch from the old Home you restart with when doing a backout plan
Hello, how do you move back the services to the preferred node?
ReplyDeleteDo you use any script?
Thanks
Hi Fernando,
DeleteUnfortunately, this is not easy; indeed, CRS does not know about these preferred / available instances setting (this is why I could not implement it in rac-status: https://unknowndba.blogspot.com/2018/04/rac-statussh-overview-of-your-rac-gi.html); to get this information, you need to srvctl config service knowing that you cannot use the GI svrctl for all the databases as it is version dependant (if you have GI 19 and DB 12, GI srvctl wont be able to list the service config for your 12c database) so you would need to set the correct env for every database and this is a mess as Oracle is very versatile so people can basically put anything they want in /etc/oratab and on top of that, the relocate syntax has changed depending on the versions . . . if you add that one could have different owners for different ORACLE_HOMEs . . . in short it is not easy, I tried a few times to make a script but I never really achieve to have a generic script knowing the previous points.
May be GI 21c (GI 20c wont be released but) would have these information then it may be easier :)
Hi,
ReplyDeleteThanks for the explanation. I have never seen any documentation or paper by Oracle stating OOP patching working for OJVM patching with less or no downtime - especially in rolling method. Only method mentioned is transient Logical standby or Goldengate.
Regards,
Saurabh
Hi,
DeleteYou can rolling patch OJVM if ... it is not heavily used; Oracle calls this a "conditional rolling" fashion.
If you are unsure if your database heavily uses Java or not, Oracle provides scripts to identify this.
Regards,
Hi,
ReplyDeleteThanks for this blog entry, it is very helpful. Does this work with shared Oracle home on ACFS clustered storage mount?
Thanks
--SJ
Hi,
DeleteI have never done it but I see no reason why it would not work.
informative post - the issue I find is, in looking to minimize db downtime w oracle 19c non-rac database - I can clone the oracle home, apply jan ru patch and ojvm patch successfully - but when I shutdown and restart the database in the new cloned/patched home - I run the datapatch piece - and it throws many ORA-29548: Java system class reported errors. OJVM patch readme instructs database to be in startup upgrade mode when running that - and it seems that the datapatch piece does not like being run after both patches are applied - as if I run the ru patch, then datapatch - then ojvm patch, then datapatch - it all completes with no issues. I have yet to find good oracle documentation as to what the issue may be and how to successfully get these to patch when doing in an out of place manner.
ReplyDeleteYou might want to consider switching to the EE/OJVM combo patches. Then it's only one opatch apply and one datapatch command. I've been doing it this way for several years without issue.
ReplyDeleteHey All, If anyone has performed similar method for grid PSU, it would be great if you can share steps like in this blog. Appreciate the help in advance.
ReplyDeleteSure I’ll post that next week, I just have to make it a nice blog.
DeletePlease let me know as I am in urgent need of this...thanks much in advance. I want to know steps for VM and ASM ..what pre-checks to be performed etc etc..
DeleteI posted the GI out of place here: https://unknowndba.blogspot.com/2021/08/grid-infrastructure-out-of-place-patching.html
DeleteTo patch the VMs ? as I said, it is exactly the sane steps as physical patching, here: https://unknowndba.blogspot.com/2018/11/how-to-patch-exadata-upgrade-exadata-18c-cells-ib.html#patching_the_db_nodes
Thanks for your great posts!
ReplyDeleteWhen running Datapatch - are you doing it with the database open and available to users, or is it not possible to have connections while running Datapatch?
Also, is there a way to further reduce time by doing rolling patch with dataguard?
Thanks
Hi,
DeleteFor datapatch, I run it while the database is (re)opened (so available to users); having said that, unless I am mistaken, I have never read any official documentation saying "you can run datapatch with the full transactional load running on your production database" but:
- In note "Datapatch User Guide (Doc ID 2680521.1)", you can read:
**************************************************************************
Datapatch uses sqlplus to run the .sql files in the patch on a single database associated with the Oracle Home, to update the data dictionary.
**************************************************************************
and also:
**************************************************************************
Opatch lays down the “binary” content and relinks any affected Oracle executables.
**************************************************************************
So clearly, opatch is the one really applying the patch and once the instances are restarted, they use the new binary(ies) so the new patch(es).
- Also, in the same note:
**************************************************************************
In a RAC environment, datapatch is run on one node, after all of the nodes have been relinked and restarted with the patched executables.
**************************************************************************
So you apply datapatch after the last instance has been patched by opatch and restarted so an "offline" or an "on maintenance" datapatch session would make no sense and would completely destroy the rolling patching concept itself.
For dataguard, this is correct ** if your patch is standby-first applicable ** which is mentioned in the patch README and which is almost always the case as far as I can tell.
Fred
Thanks Fred !
Delete